2024.6.23 好久不见。 第六学期的考试正式结束,意味着小学期的课设正式开始。水电站课程设计的任务在十天前已经下发,现在来做一个总结。 ## 使用数据
计算期初水位:173.45 优化调度最小下泄流量:4690 比较年份:1949
新任务
提取各时段的运行规则。根据水库优化调度模型求解结果,提取各时段的调度规则。
问题分析
-- 使用的数据是水库优化调度模型所得到的求解结果 -- 目前需要首先重新修正优化调度模型,修正结果,增加数据结果,形成数据总表
代码改进
在阅读文献的时候没有发现有设置汛期水位完全不变的情况,故现在对结课设计进行改变,取消汛期水位限制。另外需要将所有约束条件放入if内,修正递推函数。
目前决定重新编制优化调度代码,首先列出约束条件、初始值、递推函数,预计明天完善完成。代码如下:
代码一
1 | %%水库优化调度代码(第二版) |
今日任务
处理状态和决策离散化与时段平均出力的计算方法和具体代码。
进度
基本完成代码编制,但是数据意义还需要思考,另需要正确获取最优解的数值。
新知识点
max函数意为返回数组的最大值。
明日任务
完成动态规划代码修改
进度
昨晚进行到需要在已得到数据中提取需要的最优解的一组数据,但收工后思考之后发现,如果按照真正计算出来的所有结果来选择最优解,就失去了所谓动态规划面向时段的优势和意义,即无视了动态规划的性质——最优解的每个局部解也都是最优的。
故现在开始思考,为什么课本上和课堂上老师都在强调逆推过程而不是更加符合时间顺序的顺推过程?目前我认为,逆推时后一时段的水位和面临时段的来流可以看作八个约束条件之一,每一个时段的计算都是已知结果通过下泄流量来确定上一时段的库容和水位,依此找到确定结果的放水过程的最优解。
结论&任务
上述思想可行且所得到的结果效果很好,和结果设计版本相比有较大的完善。在结课作业中尚有一项未能完成,即惩罚因子的大小和保证率的关系。接下来寻找一下二者的函数关系。
结论
没有找到关系☹️
现附所有动态规划代码如下:
代码二
1 | %%水库优化调度代码(第二版) |
做出图像如下:
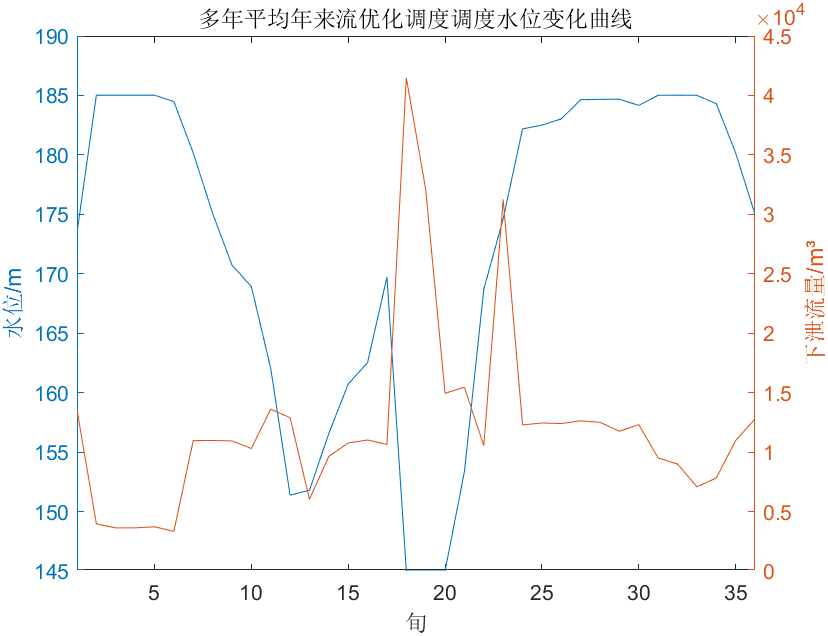
明日任务
读文献,基本得出函数关系式,基本确定编程思路,得出所有可以用于训练模型的数据。
读文献有感
具体阅读了有关NSGA-Ⅱ(Non-dominated Sorting Genetic Algorithm)的优化思路和实现方法,如果在课设报告提交前尚有时间,可以考虑把优化调度的方法从动态规划改变为NSGA。 [1] A Fast Non-dominated Sorting Genetic Algorithm For Multi-objective Optimization:NSGA-Ⅱ
粒子群优化算法(PSO)由鸟群寻找食物得到灵感,通过计算寻找“最好的”粒子,即“离食物最近的”粒子,因此可用于在已有优化调度数据的前提下拟合提取调度函数。
有一关键评价函数,优化适应度函数。用于评价每一个粒子的“好坏”,从而决定优化方向。
调度函数表达式
\[ Q_{t} = \alpha_{t} \cdot I_{t} + \beta_{t} \cdot _V{t} \]
其中,\(Q_{t}\) 为t时段下泄流量,\(I_{t}\) 为t时段入流,\(V_{t}\) 为t时段初库容.
matlab语法学习
1.函数句柄:在matlab中,函数可以像变量一样进行传递和操作。函数句柄就是指向函数的指针,可以调用函数或者将函数作为参数传递给其他函数。
2.@符号:在matlab中,@符号用于创建函数句柄。
PSO算法具体实现代码
http://t.csdnimg.cn/Xpizk
PSO算法
1 | %pop——种群数量 |
需要解决的问题
根据上述代码及文献,已经基本搞清楚PSO算法的编写过程和思路。现在需要解决的关键问题是如何设置变量内容、变量的数据结构和变量的上下界,即如何利用优化调度已经得到的数据通过PSO得到想要的参数拟合结果。
根据所找文献,他将参数按照月份进行了划分,将非汛期的每一月都进行了参数拟合计算。所以提出以下思路:
将每一月的入库流量和下泄流量作为输入参数,从1941-1990共50年,即初始种群数为50,先假设迭代次数为200。
按照文献已经得到的参数,假设需要得到的三个参数为“粒子的最优坐标”,即三维PSO问题。
明日任务
完成变量数据结构设计,初步完成PSO代码。
matlab语法学习
- num2str函数:将数字转换为字符数组
训练数据准备
按照列出的关系表达式,需要的初始数据有:当前时段的初始库容、时段入流,以及由优化调度得到的下泄流量。
依据文献所给思路,编制50年各旬下泄流量、初始库容、时段入流的数据表,即36个50×3列数据表。
训练数据使用
每一旬得到的三组数据用于拟合数据参数,相当于二元一次线性非齐次方程组求“最接近的解。对于PSO,初始搜索点的位置及速度一般是在允许的范围内随机产生的,而对于函数提取,初始点的数据即为优化调度已得到的数据。
类比可以推测,可以将时段入流和初始库容作为”初始搜索点“,即初始位置,将下泄流量作为速度。
接上述观点,既然PSO不需要初始值,是不是优化调度获得的数据其实并不能直接用于参数估计,而是作为变量范围作为参考,迭代次数增加其实是在更加逼近范围内的最优值,而最优值也是由优化调度过程给出的。所以PSO是作为反映优化调度规律,便于调度计算而使用的算法。
结果
现得到36组参数数据,还需要带入具体流量数据进行测试。
成果得出
最后得到由调度函数调度的水位变化曲线和下泄流量曲线。
修改的PSO算法代码如下:
PSO算法(修改版)
1 | %pop——种群数量 |
根据所提取的调度函数进行时段计算的代码如下:
调度函数
1 | %%利用调度函数调度(1949) |
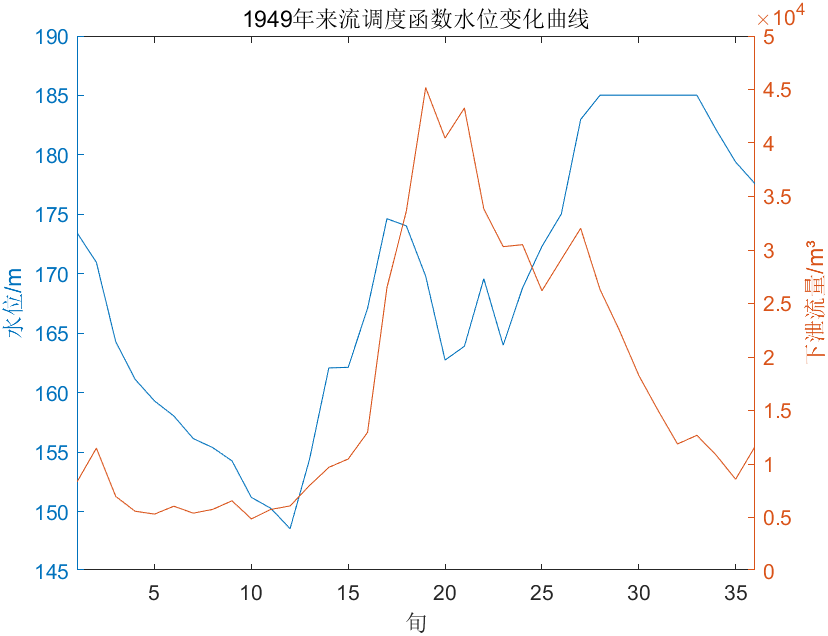
结果比较
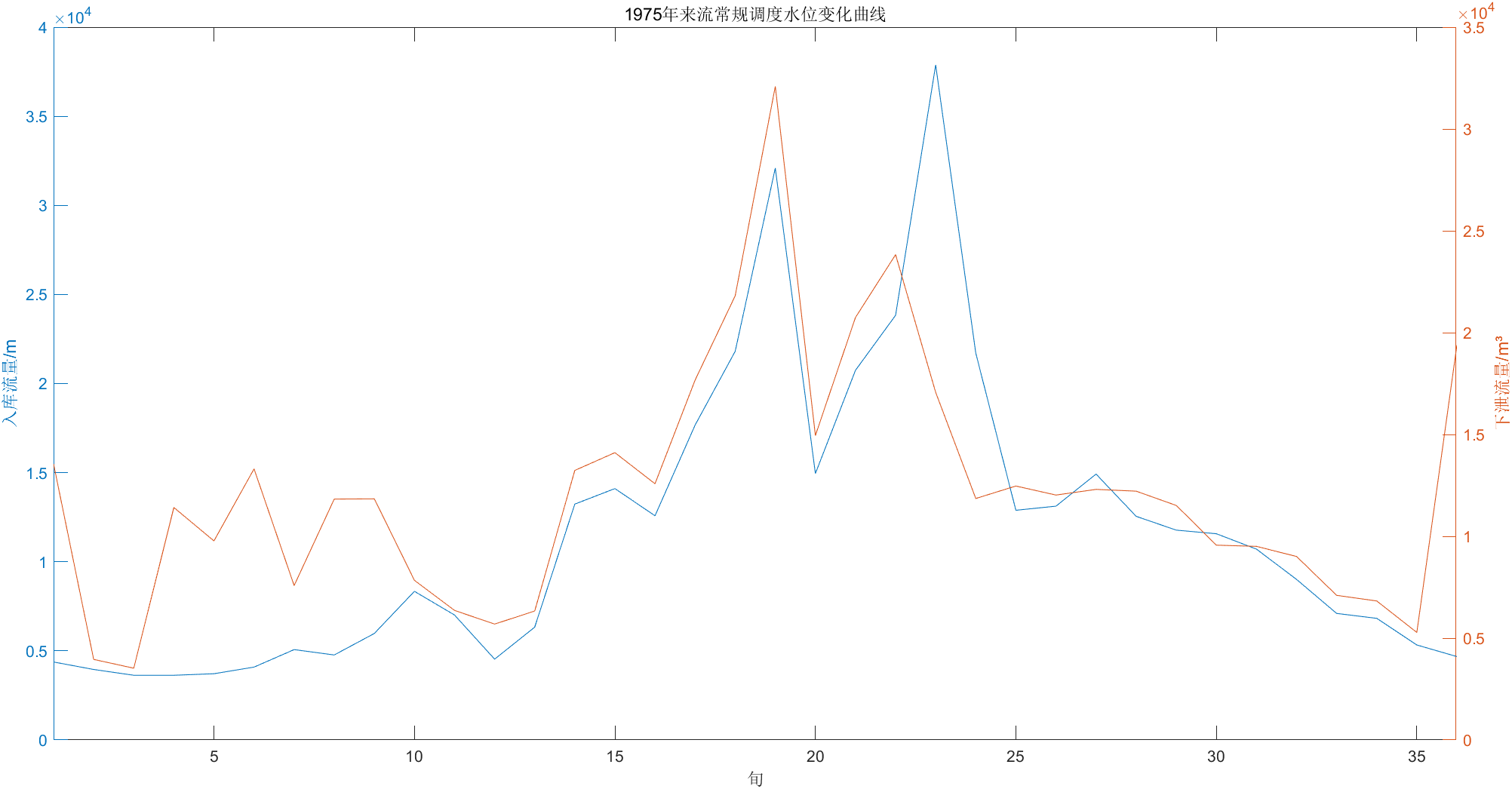
根据得出的数据对常规调度、优化调度、调度函数调度进行比较。
选择比较的参数:平均水位、发电水头、下泄流量、弃水量、保证率和总发电量。
经比较可以发现,三种方法的平均水位,平均下泄流量和发电水头差别不大,调度函数调度弃水较多,而常规调度后期水位很高,但前期为了符合调度图调度发电量较低,其中优化调度的结果较为实用。
具体比较数据见下表。
| 平均出力 | 保证率 | 平均水头 | 平均水位 | 平均下泄流量 | 弃水量 | |
|---|---|---|---|---|---|---|
| 常规调度 | 431.59 | 55% | 91.69 | 165.62 | 17364.8 | 0 |
| 优化调度 | 779.81 | 95% | 55 | 166 | 17557.44 | 0 |
| 调度图 | 445.4 | 65% | 57 | 168.77 | 17441.272 | 33039.45 |